昨天介紹了很多類型的生成模型,各類模型都有優缺點,也因為模型有缺點,所以就會有科學家與研究人員去針對這些缺點改進,接著新的模型就誕生了。今天就是要來介紹主流的生成模型之下,基於原有模型改良後誕生的新模型種類,這些模型能夠更符合人類的需求。
「人工智慧是一種讓機器能夠理解和滿足人類的需求和期望的技術。」——Stephen Hawking
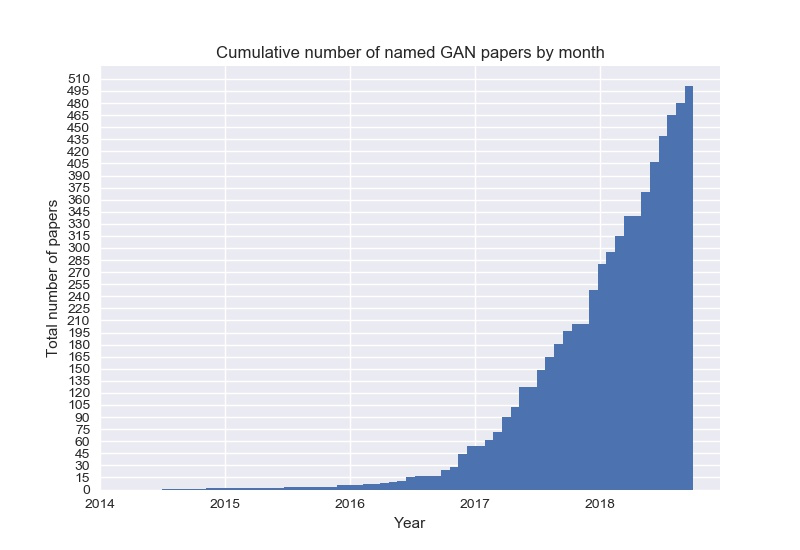
要說到GAN的種類那真的是數不盡,從2014年Ian Goodfellow以及其他學者提出了生成對抗網路這個概念後,短短幾年內與GAN有關的論文數量暴漲,論文數量如下圖,其中誕生出了許多新的GAN。基本上GAN在改變目標函數 (Objective Function)後得出的結果就會有不同變化,許多GAN也是在針對問題類型設計對應的目標函數。
目前來說有幾個比較常見的GAN模型,這些模型作為練習或者應付簡單的任務還是很好用的,以下將舉例幾個常見的GAN模型:
Deep Convolutional GAN (DCGAN):使用卷積神經網路作為生成器和判別器,提高了圖像品質和穩定性,基本上剛入門以圖像生成任務的GAN都會使用這個。因為模型比較簡單,且目標函數與原始的GAN一樣,但也是要小心訓練不穩定等問題。
Conditional GAN (CGAN):在生成器和判別器中加入額外的條件輸入,條件輸入會嵌入 (Embedding)至神經網路中,使得生成的圖片可以按照指定的條件進行控制。這解決了GAN在圖片生成時,無法控制要生成什麼圖片的問題,也可以更好的因應使用者的需求去生成對應的圖片。
Wasserstein GAN (WGAN):使用Wasserstein距離作為目標函數,Wasserstein距離是一種用來衡量兩個圖片資料之間其分布差異的方法,它可以測量把數據從一個分布轉換成另一個分布時所需要移動的平均距離的最小值,這個目標函數可以讓GAN的訓練變得更穩定,解決了原始GAN中的模式崩塌 (Mode Collapse)和難以訓練的問題。
模式崩塌簡單來說是生成器發現偷吃步的方法,就是生成同一張特定圖片時,判別器會完全分辨不出來真假,所以生成器就不會再生成其他圖片,使生成內容沒有變化且單一。
Pix2Pix:雖然名字裡面沒有GAN但他確實也是GAN的模型喔,它使用條件對抗網路和U-Net結構。U-Net是指許多下採樣層與對應的上採樣層進行連接,如下圖。任務也是圖片到圖片的變換,但是使用這個模型則需要使用成對的數據,在資料前處理上需要特別注意,最常用的方法就是把草圖轉成精緻的圖、黑白圖轉成彩色圖等。
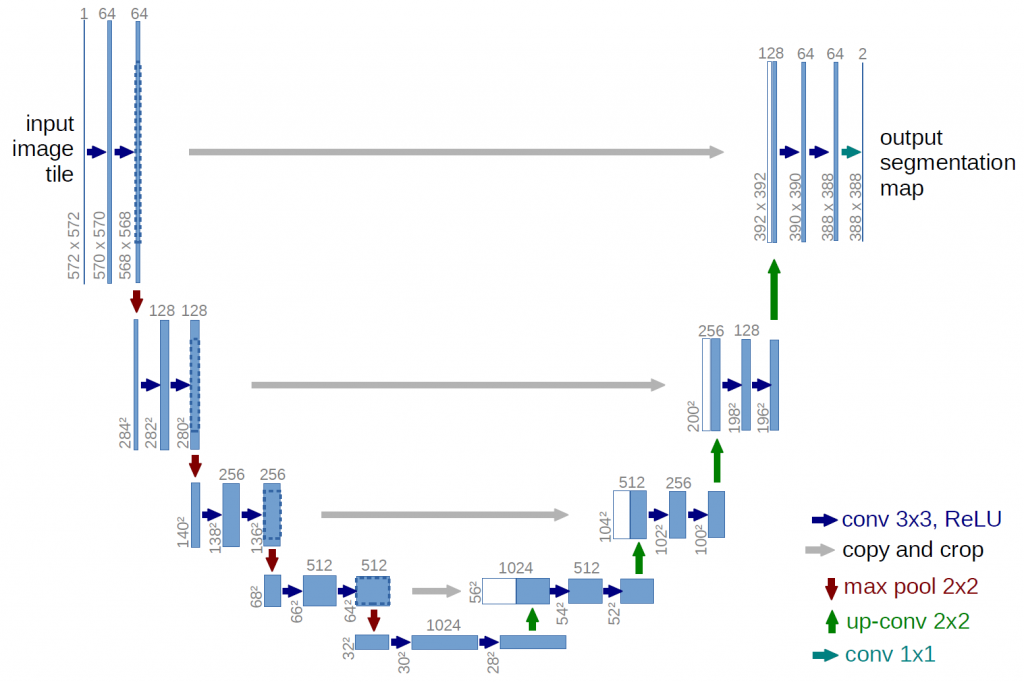
U-Net,可看到下採樣的部分 (左邊)與上採樣 (右邊)的部分會連接起來。[圖源]

CycleGAN的風格變換。[圖源]
StyleGAN:使用風格轉換網路和自適應實例歸一化 (Adaptive Instance Normalization),可以用於高質量和高分辨率的人臉圖像生成,有很多逼真人臉生成的應用都會使用這個GAN來實現。
BigGAN:使用大量的資料集和深層架構,資料集因為資料集量多且內容豐富,基本上可以當成把很多資料集一起丟進去訓練,訓練出來的模型就可以實現了高質量和高多樣性的圖像生成。不過因為使用深層架構所以要小心梯度消失的問題,要避免可以使用殘差網路 (Residual Networks)。
梯度消失是指在深層的網路中訓練,因為反向傳播不斷地取偏導數,導致反向傳播後面的層數梯度越來越小甚至直接為0,梯度一但為0在之後的優化時神經網路的權重就不會有變化,導致神經網路無法收斂、優化。
StarGAN:使用多域對抗學習和屬性控制向量,與Cycle GAN類似,但Cycle GAN只能在兩個風格間變換,而StarGAN可以在多個風格之間進行變換。
SRGAN (Super Resolution GAN):使用感知損失 (Perceptual Loss)和一般GAN的對抗損失 (Adversarial Loss),訓練出來的模型可以將低解析度的圖片轉換成高解析度的圖片,實現了超分辨率的圖像重建。
PGGAN (Progressive Growing of GAN):使用漸進式增長的訓練策略,簡單來說就是在訓練中逐漸增加生成器和判別器的神經網路層數,從很簡單的任務開始慢慢增加難度的概念。好處是可以提高圖片的質量與多樣性並且可以增進訓練的穩定性。壞處是對電腦的性能有一定的要求TT。
InfoGAN:使用Mutual Information作為目標函數,而且通過最大化生成器的一小部分隱變量和觀察之間的Mutual Information,來學習根據指定條件生成對應的資料。這樣做的好處是可以讓生成器的輸出可以吻合我們指定的條件,與CGAN類似,只是更精細,可以調整生成圖片中物件的長度,方向形狀等。
StackGAN:使用了兩個階段的訓練來將文字轉化為一張高解析度圖片,第一階段訓練是將文字敘述轉換為低解析度的圖片,接著將這個圖片送到第二階段的生成模型裡面,再生成高解析度的圖片。基本上被用來做文字轉圖片的應用。
目前AE模型共有四個大類別,詳情可以參考這篇文章。文章中介紹了目前較常見的四大種AE模型 (AE, VAE, DAE, SAE),當然除此之外還有很多可以介紹的,目前常見的模型如下:
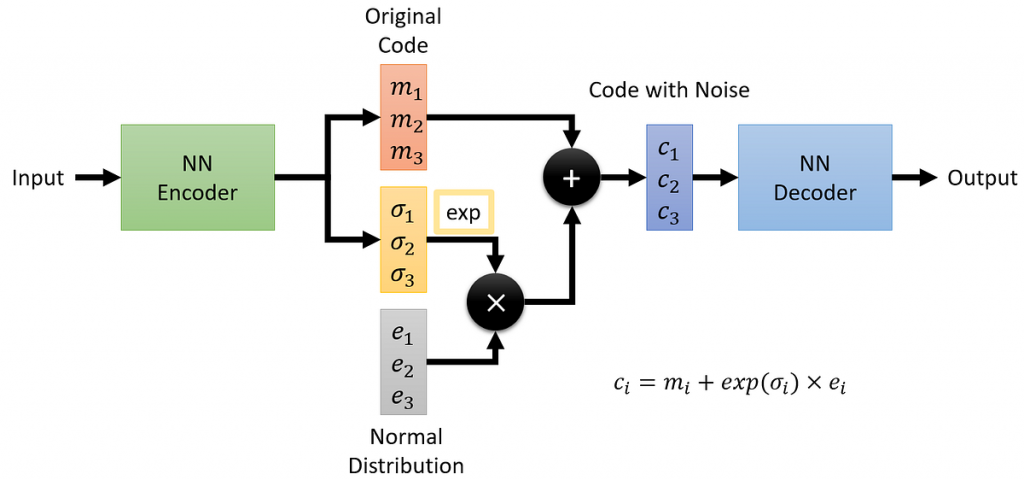
VAE在採樣低維向量的方式。[圖源]
Sparse Auto Encoder (SAE):這個作法是在一般的AE上做L1正規化,這使整個模型中某些神經元的輸出變為0,從而增加模型的稀疏性。這麼做的好處是可以將沒用的訊息捨棄掉,從而提升對圖片整體的特徵描述。
Adversarial Auto Encoder:這是一種結合了GAN的自動編碼器,也稱AEGAN,它可以通過一個判別器來強制隱藏層的向量符合某種分佈,從而提高生成質量和多樣性,生成模型就是AE或者VAE (文獻中貌似比較常使用VAE),不過訓練AE不是直接計算損失,而是再使用判別器來幫忙訓練AE的生成能力。
Attention Auto Encoder:這是一種利用注意力機制來增強AE的表達能力的模型,它可以通過關注輸入資料的重要部分來提高重建效果和降噪能力。
注意力機制就是使模型能夠特別注重某些區塊的機制,這使得模型會針對某些部分給予更高的權重或關注度。
Concatenated Auto Encoder:這比較類似是一種概念,其原理是一種將多個自動編碼器的隱藏層向量串接起來的模型,它可以通過增加隱藏層的維度來提高資料的表示能力和重建精度。使用多個不同類型的Auto Encoder組合起來,使得資料可以同時具有不同的特性與能力,例如去噪、生成圖片、圖像修復等。
:這個模型要訓練出什麼樣的能力?去噪?生圖?還是圖像修復?
Concatenated Auto Encode:
因為擴散模型是相當新穎的模型,故沒有太多模型種類,基本上與GAN改變目標函數不同,擴散模型是藉由改變擴散過程的方式等,來實現不同的任務類型。基本上最原始的擴散模型就是去噪擴散機率模型 (Denoising Diffusion Probabilistic Models, DDPM)與改良版的去噪擴散隱式模型 (Denoising Diffusion Implicit Models, DDIM),除此之外Stable Diffusion也是同樣基於擴散模型的應用,接下來就來個別介紹這些模型。
擴散模型與自動編碼器在模型架構上類似,但訓練方式與目標卻有一點差別,自動編碼器是將圖片轉為低維資料再還原;擴散模型是將圖片轉為雜訊資料再還原。
Denoising Diffusion Probabilistic Models (DDPM):是最基本的擴散模型,模型架構基本上類似AE,通常使用U-Net等深度模型。這個模型會利用馬可夫鏈 (Markov Chain)的性質進行採樣,逐步為圖片添加雜訊,直到圖片完全成為雜訊圖。在這過程中會有產生許多隱變量,這些隱變量就是添加不同程度雜訊的圖片。接著訓練模型逐步去噪,DDPM的目標是學習這些隱變量的機率密度函數,並利用逆向擴散過程來還原圖片、生成高質量的圖像等資料。DDPM的優點是可以有效地處理高維度和多模態的圖片生成,而且訓練比較穩定。
使用馬可夫鏈採樣真的會導致訓練時間被拉長很多。所以訓練DDPM時請保持耐心。
Denoising Diffusion Implicit Models (DDIM):DDIM是DDPM的一種變體,它不需要明確地計算資料的概率密度函數,而是利用隨機過程的性質對資料分佈進行建模,採樣方式也不是使用馬可夫鍊而是使用別的方式進行計算,這點之後會詳細介紹,但整體上訓練目標與DDPM一樣。DDIM的採樣速度比DDPM快得多,且效果與DDPM一樣,故在模型選擇上我會推薦使用這個模型。但不代表DDPM不重要,因為它還是擴散模型的始祖,其理論、概念都非常重要。
速度快真的是好事,訓練起來心情比較舒爽!
Stable Diffusion:這個模型應該是最廣為人知的模型了,他強大的生成能力令人驚嘆,有許多AI繪圖作品也都是經由這模型生成的,這個模型也是基於擴散模型的,然後模型分成文本編碼器 (Text Encoder, 藍色)、圖片訊息生成器 (Image Information Creator, 粉色)、圖片解碼器 (Image Decoder黃色)。
Stable Diffusion模型架構。[圖源]
其中來簡單解釋一下文本編碼器、圖片訊息生成器、圖片解碼器吧。
文本編碼器:這個部分的任務是將文字訊息轉成一段語意向量,這段向量代表這段文字,只是變成模型看得懂的形式。順帶一提文本編碼器所使用的模型是CLIP模型,簡單來說就是利用文字訊息監督學習,將分類任務變成圖片與文字的匹配任務。
圖片訊息生成器:這個部分是此模型性能優秀的重要因素。與一般擴散模型不同,這個圖片訊息生成器會產生一張低解析度的圖片資料,這個資料會再被送入圖片解碼器還原成高解析度的圖片。另外文本編碼器的語意向量也會作為條件輸入輸入到這個部分裡面,使得生成內容可以被控制。
保證性能提升的同時卻也大幅地增加了運算量,所以這個模型也是一般的電腦跑不出來的。
圖片解碼器:輸入為圖片信息生成器的低解析圖片,接著進行上採樣將圖片放大後即為完整圖片。
今天介紹了一些生成模型的種類,不過其實生成模型種類真的非常多樣,除了圖像資訊以外這些模型也被廣泛的應用於各類任務中,包括訊號生成、機器人動作生成、醫學影像生成等,可以結合的領域真的太多了XD。明天會更加詳細的介紹生成對抗網路的原理等,雖然會牽扯到一些數學,可能很煩但確實非常重要!希望大家可以打起精神,讓我來帶你們走入GAN的殿堂。

